Ho fortunosamente recuperato il listato in R per il tutorial sulla rappresentazione spazio-stato e sull'uso del filtro di Kalman per la stima dei parametri.
L'ho aggiornato e ho modificato i commenti in Inglese in modo da renderlo più vicino all'analisi di dati finanziari.
Rispetto agli esempi di Jouni Helske - che naturalmente ringrazio per essersi preso la briga di scrivere le funzioni usate per la rappresentazione e il filtro - io ho aggiunto l'applicazione allo SPY con relativo trading system fallimentare a dimostrazione che il trend following con una media mobile non è affatto ciò che si pensa che sia.
Sperando di fare cosa gradita (ma questo è veramente di nicchia, temo ), copiate in R e lanciate; nella sezione del back test alcune righe richiedono diversi minuti di elaborazione.
), copiate in R e lanciate; nella sezione del back test alcune righe richiedono diversi minuti di elaborazione.
Se lanciate riga per riga anzichè tutto, sicuramente si capisce di più quello che state facendo.
(Mi scuso per eventuali bestialità anglosassoni nei commenti, ma l'assenza di un correttore di ortografia rende molto più probabile che abbia disseminato errori ortografici qua e là).
L'ho aggiornato e ho modificato i commenti in Inglese in modo da renderlo più vicino all'analisi di dati finanziari.
Rispetto agli esempi di Jouni Helske - che naturalmente ringrazio per essersi preso la briga di scrivere le funzioni usate per la rappresentazione e il filtro - io ho aggiunto l'applicazione allo SPY con relativo trading system fallimentare a dimostrazione che il trend following con una media mobile non è affatto ciò che si pensa che sia.
Sperando di fare cosa gradita (ma questo è veramente di nicchia, temo
), copiate in R e lanciate; nella sezione del back test alcune righe richiedono diversi minuti di elaborazione.Se lanciate riga per riga anzichè tutto, sicuramente si capisce di più quello che state facendo.
(Mi scuso per eventuali bestialità anglosassoni nei commenti, ma l'assenza di un correttore di ortografia rende molto più probabile che abbia disseminato errori ortografici qua e là).
Codice:
[COLOR="Teal"]# ================================================================== #
# Kalman filter: a cuttin' edge framework for financial time series? #
# By Cren (and thanks to Jouni Helske for functions) #
# ================================================================== #
# Index:
## 1. meeting Kalman filter with examples
## 2. using Kalman filter like a moving average
## 3. rollapplying Kalman filter to see differences with static estimation
## 4. building univariate state-space models
## 5. building multivariate state-space models
## 6. conclusions
# Loading package[/COLOR]
library(ggplot2)
library(gmp)
library(KFAS)
library(quantmod)
library(PerformanceAnalytics)
[COLOR="teal"]## 1. meeting Kalman filter with examples
# Example of local level model for Nile series[/COLOR]
y <- Nile
qplot(y = y, x = index(y), geom = 'line', ylab = 'Nile', xlab = 'Year')
[COLOR="teal"]# Function 'structSSM' creates a state space representation of structural time
# series[/COLOR]
modelNile <- structSSM(y = y)
[COLOR="teal"]# Function 'fitSSM' finds the maximum likelihood estimates for unknown
# parameters of an arbitary state space model if an user defined model building
# function is defined. As a default, 'fitSSM' estimates the non-zero elements,
# which are marked as NA, of the time-invariant covariance matrices H and Q of
# the given model.[/COLOR]
fit <- fitSSM(inits = c(0.5 * log(var(Nile)), 0.5 * log(var(Nile))),
model = modelNile)
[COLOR="teal"]# Filtering and state smoothing: performs Kalman filtering and smoothing with
# exact diffuse initialization using univariate approach for exponential family
# state space models. For non-Gaussian models, state smoothing is provided with
# additional smoothed mean and variance of observations[/COLOR]
kfsNile <- KFS(fit$model, smoothing = 'state')
[COLOR="teal"]# Simple plot of series and the smoothed 'signal = Z * alpha_hat'[/COLOR]
plot(kfsNile, col = 1:2, lwd = 1:2) ; grid()
[COLOR="teal"]# Confidence intervals for the state[/COLOR]
lows <- c(kfsNile$alphahat - qnorm(0.95) * sqrt(c(kfsNile$V)))
ups <- c(kfsNile$alphahat + qnorm(0.95) * sqrt(c(kfsNile$V)))
plot.ts(cbind(y, c(kfsNile$alphahat), lows, ups), plot.type = 'single',
col = c(1:2, 3, 3), ylab = 'Predicted annual flow', main = 'River Nile',
lwd = c(1, 2, 2, 2)) ; grid()
[COLOR="teal"]# Example of multivariate local level model with only one state
# Two series of average global temperature deviations for years[/COLOR]
data(GlobalTemp)
[COLOR="teal"]# Function 'SSModel' creates a state space object of class 'SSModel' which
# can be used as an input object for various functions of KFAS package[/COLOR]
modelTemp <- SSModel(y = GlobalTemp, Z = matrix(1, nrow = 2), T = 1, R = 1,
H = matrix(NA, 2, 2), Q = NA, a1 = 0, P1 = 0, P1inf = 1)
[COLOR="teal"]# Estimating the variance parameters[/COLOR]
fit <- fitSSM(inits = c(0.5 * log(.1), 0.5 * log(.1), 0.5 * log(.1), 0),
model = modelTemp)
outTemp <- KFS(fit$model, smooth = 'both')
ts.plot(cbind(modelTemp$y, t(outTemp$alphahat)), col = 1:3,
lwd = c(1, 1, 2)) ; grid()
legend('bottomright',legend = c(colnames(GlobalTemp), 'Smoothed signal'),
col = 1:3, lty = 1, lwd = c(1, 1, 2))
[COLOR="teal"]# Example of multivariate series where first series follows stationary ARMA(1,1)
# process and second stationary AR(1) process
[/COLOR]
y1 <- arima.sim(model = list(ar = 0.8, ma = 0.3), n = 100, sd = 0.5)
[COLOR="teal"]# Function 'arimaSSM' creates a state space representation of ARIMA model[/COLOR]
model1 <- arimaSSM(y = y1, arima = list(ar = 0.8, ma = 0.3), Q = 0.5 ^ 2)
y2 <- arima.sim(model = list(ar = -0.5), n = 100)
model2 <- arimaSSM(y = y2, arima = list(ar = -0.5))
model <- model1 + model2
f.out <- KFS(model)
[COLOR="teal"]# Drivers[/COLOR]
Seatbelts
model <- structSSM(y = log(Seatbelts[,'drivers']), trend = 'level',
seasonal = 'time', X = cbind(log(Seatbelts[,'kms']),
log(Seatbelts[,'PetrolPrice']),
Seatbelts[, c('law')]))
fit <- fitSSM(inits = rep(-1, 3), model = model)
out <- KFS(fit$model, smoothing = 'state')
plot(out, lty = 1:2, col = 1:2, main = '')
[COLOR="teal"]# Function 'signal' extracts the filtered or smoothed signal of a State Space
# model depending on the input object
[/COLOR]
lines(signal(out, states = c(1, 13:15))$s, col = 4, lty = 1)
legend('bottomleft', legend = c('Observations', 'Smoothed signal',
'Smoothed level'), col = c(1, 2, 4),
lty = c(1, 2, 1))
[COLOR="teal"]# Multivariate model with constant seasonal pattern in frequency domain[/COLOR]
model <- structSSM(y = log(Seatbelts[,c('front', 'rear')]), trend = 'level',
seasonal = 'freq', X = cbind(log(Seatbelts[,c('kms')]),
log(Seatbelts[,'PetrolPrice']),
Seatbelts[,'law']), H = NA,
Q.level = NA, Q.seasonal = 0)
sbFit <- fitSSM(inits = rep(-1, 6), model = model)
out <- KFS(sbFit$model, smoothing = 'state')
ts.plot(signal(out, states = c(1:2, 25:30))$s, model$y, col = 1:4)
[COLOR="teal"]# What have we learnt so far?
# a. We can use either 'SSModel' and 'structSSM' to build up a state-space
# model;
# b. 'fitSSM' allows us to estimate maximum likelihood variance of the model
# c. 'KFS' performs the Kalman filter
# d. 'signal' extracts the filtered or smoothed signal of a State Space
# model depending on the input object
## 2. using Kalman filter like a moving average[/COLOR]
getSymbols('SPY', from = '1950-01-01', src = 'yahoo')
obs <- SPY
y <- log(Cl(to.daily(obs)))
chartSeries(y)
[COLOR="teal"]# State-space model:
# y(t) = Z * alpha(t) + e(t), e(t) ~ N(0, H(t))
# alpha(t + 1) = T * alpha(t) + R(t) * h(t), h(t) ~ N(0, Q(t))[/COLOR]
model <- SSModel(y = as.ts(y), Z = 1, T = 1, H = 1, Q = 1)
[COLOR="teal"]#fit <- fitSSM(inits = rep(0.5 * log(.1), 2), model = model)[/COLOR]
out <- KFS(object = model, smoothing = 'state')
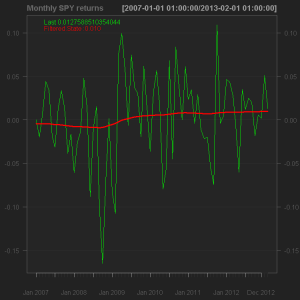
plot(out, col = 1:2) ; grid()
[COLOR="teal"]# Note that using MLE fit on a in-sample financial time series may return a
# perfect fit, which is not the result we would like to get. By the way,
# there's no difference in using specific diagonal variance matrices elements
# unless these variables are set equal to NULL or MLE parameters
## 3. rollapplying Kalman filter to see differences with static estimation
# Kalman filter smoothing function with MLE
# State-space model:
# y(t) = Z * alpha(t) + e(t), e(t) ~ N(0, H(t))
# alpha(t + 1) = T * alpha(t) + R(t) * h(t), h(t) ~ N(0, Q(t))[/COLOR]
ks <- function(y){
y <- Cl(to.monthly(y))
y <- log(as.ts(y))
model <- SSModel(y = y, Z = 1, T = 1, H = NA, Q = NA)
fit <- fitSSM(inits = rep(0.5 * log(.1), 2), model = model)
out <- KFS(object = fit$model, smoothing = 'state')
return(exp(tail(t(out$alphahat), 1)))
}
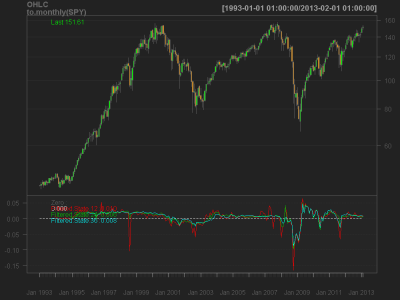
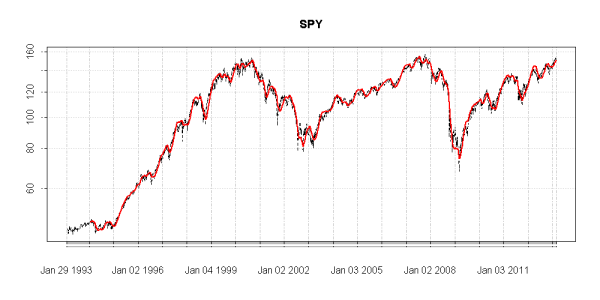
KFMA <- rollapplyr(data = Cl(obs), width = 252 * 2, FUN = ks)
plot.xts(SPY, log = 'y')
lines(KFMA, col = 2, lwd = 1)
[COLOR="teal"]# A small variation: LOESS featuring Kalman filter
# State-space model:
# y(t) = Z * alpha(t) + e(t), e(t) ~ N(0, H(t))
# alpha(t + 1) = T * alpha(t) + R(t) * h(t), h(t) ~ N(0, Q(t))
# Here y(t) is the LOESS value[/COLOR]
lks <- function(y, span){
y <- log(y)
x <- 1:length(y)
loess <- loess(formula = y ~ x, span = span)
y <- as.ts(loess$fitted)
model <- SSModel(y = y, Z = 1, T = 1, H = NA, Q = NA)
fit <- fitSSM(inits = rep(0.5 * log(.1), 2), model = model)
out <- KFS(object = fit$model, smoothing = 'state')
return(exp(mean(tail(t(out$alphahat), 5))))
}
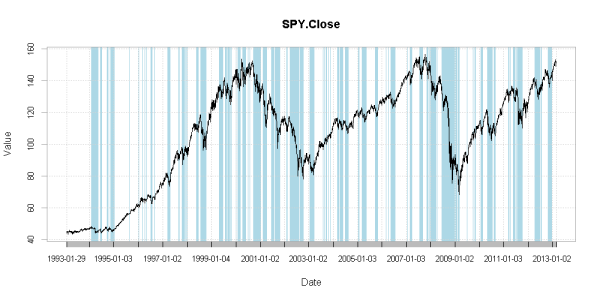
KFMA <- rollapplyr(data = Cl(obs), width = 252, FUN = lks, span = .95)
plot.xts(SPY, log = 'y', lty = 2)
lines(KFMA, col = 2, lwd = 2)
trig <- ifelse(KFMA >= lag(KFMA), 1, 0)
per.ar.0 <- index(trig[trig != lag(trig)])
if(is.whole(length(per.ar.0) / 2) == FALSE){
per.ar <- c(per.ar.0, index(tail(KFMA, 1)))
} else{
per.ar <- per.ar.0
}
period.areas <- NULL
for(i in seq(1, length(per.ar), 2)){
period.areas[i] <- paste(per.ar[i], per.ar[i + 1], sep = '/')
}
period.areas <- na.omit(period.areas)
chart.TimeSeries(R = Cl(obs), log = 'y', period.areas = period.areas,
period.color = 'lightblue', lwd = 1)
[COLOR="teal"]# Equity line of basic trading system[/COLOR]
ret.cc <- ClCl(obs)
ret.oc <- OpCl(obs)
ret <- lag(trig) * ifelse(lag(trig) != lag(trig, 2), ret.oc, ret.cc)
charts.PerformanceSummary(R = ret)
[COLOR="teal"]# This shows you cannot really use a low-pass filter to trade prices because of
# unavoidable lag, while Kalman filter cannot "see" trend components beyond
# noise more than a simple moving average can do
## 4. building univariate state-space models
# Summary (again):
# a. We can use either 'SSModel' and 'structSSM' to build up a state-space
# model;
# b. 'fitSSM' allows us to estimate maximum likelihood variance of the model
# c. 'KFS' performs the Kalman filter
# d. 'signal' extracts the filtered or smoothed signal of a State Space
# model depending on the input object
# State-space model:
# y(t) = Z * Alpha(t) + E(t), E(t) ~ N(0, H(t))
# Alpha(t + 1) = T * Alpha(t) + R(t) * H(t), H(t) ~ N(0, Q(t))
# Hence Alpha, E and H are matrices[/COLOR]
[COLOR="teal"]# We've already seen the 'Seatbelts' data frame: how have 'PetrolPrice' and
# 'law' affected 'DriversKilled' over time?
[/COLOR]
(Seatbelts)
model <- structSSM(y = log(Seatbelts[,'DriversKilled']),
X = cbind(log(Seatbelts[,'PetrolPrice']),
Seatbelts[,'law']), H = NA, Q.level = NA)
fit <- fitSSM(inits = rep(.5 * log(.1), 2), model = model)
out <- KFS(object = fit$model, smoothing = 'state')
Beta <- matrix(NA, nrow = nrow(Seatbelts), ncol = 3)
for(i in 1:3){
Beta[,i] <- signal(out, i)$signal
}
colnames(Beta) <- c('Intercept', 'Beta 1', 'Beta 2')
plot.zoo(Beta, xaxt = 'n', xlab = '')
[COLOR="teal"]## 5. building multivariate state-space models
# State-space model:
# Y(t) = Z * Alpha(t) + E(t), E(t) ~ N(0, H(t))
# Alpha(t + 1) = T * Alpha(t) + R(t) * H(t), H(t) ~ N(0, Q(t))
# Hence Y, Alpha, E and H are matrices[/COLOR]
Seatbelts
model <- structSSM(y = cbind(log(Seatbelts[,'DriversKilled']),
log(Seatbelts[,'drivers'])),
X = cbind(log(Seatbelts[,'PetrolPrice']),
Seatbelts[,'law']))
fit <- fitSSM(inits = rep(.5 * log(.1), 4), model = model)
out <- KFS(object = fit$model, smoothing = 'state')
[COLOR="teal"]# Checking differences between filtered states and OLS regression coefficients
[/COLOR]
Y <- cbind(log(Seatbelts[,'DriversKilled']), log(Seatbelts[,'drivers']))
X <- cbind(log(Seatbelts[,'PetrolPrice']), Seatbelts[,'law'])
summary(lm(Y ~ X))
plot(signal(object = out, states = 3:4)$signal, main = '')
[COLOR="teal"]## 6. conclusions
# What have we learnt about state - space models and Kalman filter?
# State - space representation is suitable to describe linear models, like
# structural time series and linear regressions. State - space model time
# varying parameters can be estimated via Kalman filter: maximum likelihood is
# used to get residuals covariance matrices, and a smoothed state signal can be
# obtained.
# What Kalman filtered state - space represention CANNOT do: to extract a trend
# component which could be "followed" to gain profits from financial
# instruments' time series.
# What Kalman filtered state - space represention CAN do: to model every
# linear relation out there regardless of time series sample dimensions; every
# time series analysis practitioner has always found difficulties in sampling
# financial time series to perform parameters estimation, that is why expanding
# and/or rolling window are broadly used.[/COLOR]Allegati
Ultima modifica: