the learner
Nuovo Utente
- Registrato
- 23/2/07
- Messaggi
- 965
- Punti reazioni
- 33
Ciao,
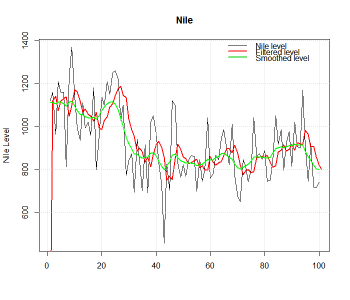
Leggendo vari papers sul modello HAR-RV del prof. Corsi sembra che l'utilizzo della realized variance a 1g, 5gg e 21gg nel modello dia migliori risultati out of sample rispetto ad altri modelli per la previsione della volatilità.
Chi lo utilizza? Con che finalità (es. nel trading in opzioni)?
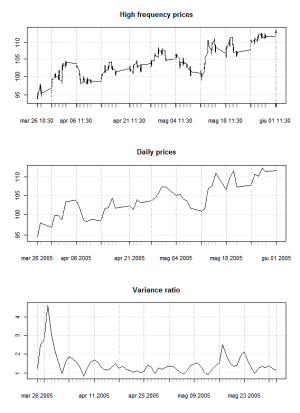
È possibile usare le RV nel calcolare il variance ratio per identificare mean reversion nella serie dei prezzi?
Quello della RV sembra un tema molto interessante. Spero in qualche testimonianza di utilizzo.
Grazie.
Leggendo vari papers sul modello HAR-RV del prof. Corsi sembra che l'utilizzo della realized variance a 1g, 5gg e 21gg nel modello dia migliori risultati out of sample rispetto ad altri modelli per la previsione della volatilità.
Chi lo utilizza? Con che finalità (es. nel trading in opzioni)?
È possibile usare le RV nel calcolare il variance ratio per identificare mean reversion nella serie dei prezzi?
Quello della RV sembra un tema molto interessante. Spero in qualche testimonianza di utilizzo.
Grazie.
")